
This breakthrough enables a robotic arm to effectively learn how to pick up and place objects from the ground in real-world environments. SAC-X is built on the concept of learning complex tasks from scratch, where an agent must first acquire a set of fundamental skills. Just like a baby needs to develop coordination and balance before crawling or walking, SAC-X provides agents with intrinsic goals that correspond to basic skills, enhancing their ability to tackle more complicated tasks over time.
Researchers believe that SAC-X is a versatile reinforcement learning approach that can be applied beyond robotics, opening new possibilities for AI in various domains.
Whether it's children or adults, organizing things often proves difficult without clear guidance. Training AI agents to organize is even more challenging. To succeed, agents must master key visual-motor skills such as approaching an object, grasping it, opening a container, and placing the object inside. The complexity increases when these actions must be performed in the correct sequence.
For control tasks like tidying a desk or stacking objects, the agent must coordinate its simulated arms and nine finger joints, considering three critical factors: how, when, and where to move. Only by mastering this can the task be completed successfully.
At any moment, the number of possible movement combinations is vast, and identifying the correct sequence of actions leads to a significant challenge in reinforcement learning. This has become a central area of research, especially for tasks requiring precise control.
Techniques like reward shaping, apprenticeship learning, or learning from demonstration can help address these issues. However, they typically require substantial prior knowledge. Learning complex control problems with minimal pre-existing knowledge remains a major challenge in the field.
Our recent paper introduces a novel learning paradigm called Scheduled Auxiliary Control (SAC-X), which aims to overcome these limitations by using structured auxiliary tasks to guide the learning process.
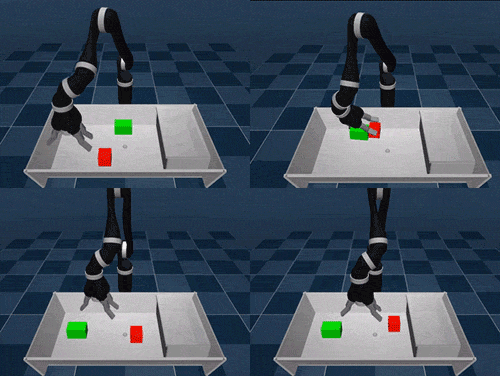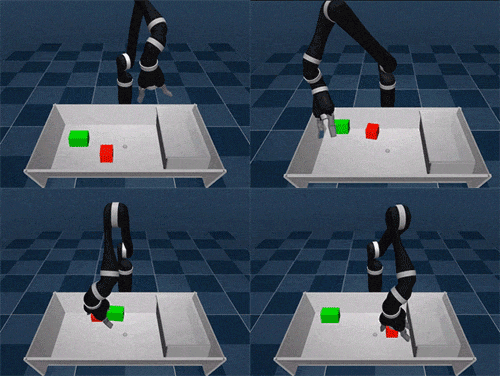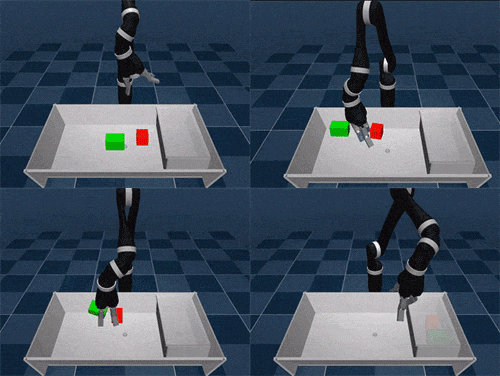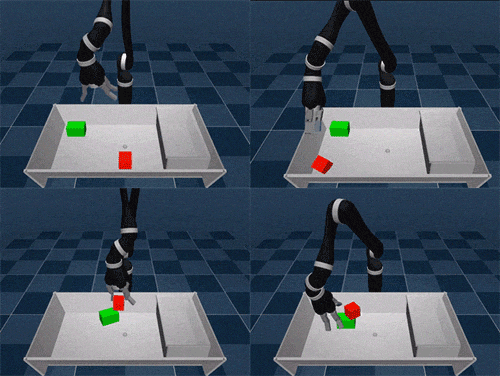
SAC-X is based on the idea of learning complex tasks from scratch, where an agent must first master a set of basic skills. Just like a baby needs to develop coordination and balance before moving, SAC-X gives agents intrinsic goals that help them build up to more complex behaviors.
We tested SAC-X in both simulated and real-world robot tasks, including stacking different objects and placing them into boxes. The auxiliary tasks we designed follow a general principle: encouraging agents to explore their sensory space.
For example, the agent might activate tactile sensors on its fingers, sense wrist strength, maximize joint angles using body sensors, or ensure the object stays within the visual range. A simple reward is given if the goal is achieved, and zero otherwise.

The agent starts by activating the tactile sensor on its finger and then moves the object accordingly.

Simulated agents eventually master complex stacking tasks through repeated exploration and learning.
Once the agent learns these skills, it can decide its current "intent," whether to focus on a secondary task or an externally defined goal. It's crucial that the agent can detect and learn from sparse reward signals, even when not directly guided by external instructions. For instance, while picking up or moving an object, the agent might accidentally stack them and receive a "stack reward." These small successes help the agent build up its understanding of what to do next.
Based on the indirect knowledge gathered during training, the agent creates a personalized learning path. This approach is highly efficient, especially in environments where external rewards are rare or delayed.
The scheduling module helps the agent determine its next intent. Using meta-learning, the scheduler improves during training, aiming to maximize progress on the main task and significantly improving data efficiency.

After exploring many internal auxiliary tasks, the agent learns how to stack and organize items effectively.
Evaluation results show that SAC-X can complete all tasks from scratch, using the same set of auxiliary tasks throughout. What’s exciting is that our lab’s robotic arm successfully learned to pick and place objects without prior exposure—something previously considered very difficult due to the need for efficient data in real-world settings.

For real robotic arms, SAC-X enables them to lift and move green cubes, even though they have never encountered such tasks before.
We believe SAC-X represents a significant step toward true zero-shot learning, where only the overall goal needs to be defined. SAC-X allows for flexible auxiliary tasks based on general perceptions, ultimately covering tasks deemed important by researchers. In this sense, SAC-X is a general-purpose reinforcement learning method, suitable for sparse reward environments beyond robotics and control systems.
The Future Intelligence Lab is a collaborative research institute combining artificial intelligence, internet technology, and brain science, established by scientists and institutions from the Academy of Sciences.
Its main objectives include developing an AI IQ evaluation system, conducting global AI IQ assessments, and creating an Internet (city) cloud brain research plan. The lab aims to enhance enterprise, industry, and city intelligence levels through advanced technological solutions.
Usb3.2 20Gbps Data Cable,Usb 3.2 Type-C,Usb3.2 Type-C Charging Data Cable,High-Speed Usb 3.2 Type-C
Dongguan Pinji Electronic Technology Limited , https://www.iquaxusb4cable.com