
Introduction: The 2016 International Artificial Intelligence Conference (IJCAI2016) was held from July 9 to July 15. This year's conference focused on artificial intelligence of human consciousness. This article was received by IJCAI2016. In addition to the detailed explanation of the paper, we also invited Associate Professor Li Yanjie of Harbin Institute of Technology to comment.
Visual tracking based on reliable memory
Joint compilation: Blake, Zhang Min, Chen Chun
Summary
In this article, we propose a new visual tracking architecture that intelligently finds reliable patterns in a large number of videos to reduce offset errors in long-term tracking tasks. First, we designed a DFT-based visual tracker that can track a large number of samples while ensuring real-time performance. Then we propose a new clustering approach that uses time constraints. It can find and remember the corresponding patterns from previous screens. We call it "reliable memory." With this method, our tracker can use uncontaminated information to reduce the offset problem. The implementation results show that our tracker achieves the best performance on the current benchmark data set. Furthermore, it can solve the problem of robust tracking in long videos with more than 4000 frames, but other methods cannot accurately track the number of frames in the early frames.
1 Introduction
In the fields of computer vision and artificial intelligence, visual tracking is a basic but challenging problem. Although many advances have been made in recent years, there are still many unsolved problems. Because of its complexity in many factors, such as changes in brightness and angle, chaotic environment, and shape distortion and shielding and other issues. A large number of studies related to visual tracking have adopted a detection tracking framework. By applying existing machine learning methods (usually judgmental) and online learning techniques, these methods have achieved good results. In order to model different performance changes, they tested and updated a large number of samples. However, all of them encountered the same dilemma: Although more samples can bring better accuracy and adaptability, but also increase the risk of computational costs and offset.
In order to make better judgments, Ross et al. used a general-purpose model of revision-rate to record changes in target performance. The learning-rate is essentially a compromise between adaptability and stability. However, under a very small learning rate, the effect of their model on the previous sample is still exponentially dropped in the number of frames, and the offset error is still rising. In order to reduce offset errors, Babenko et al. designed to find hidden structure information around the target area. By combining the first frame of tagged samples with the samples in the tracking process, other methods try to establish such a model to avoid offset errors. However, few samples can be seen as "very definitive," which in turn limits their robustness in long-term challenging tasks. Recently, various methods use Discrete Fourier Transform (DFT) for fast detection and achieve the highest accuracy at the lowest computational cost. However, as with other common methods, the memory length of their models is limited by a modified forgetting rate, so they still have cumulative offset errors in long-term tasks.
There is a very important observation - when the tracked target moves smoothly and without occlusion or rotation, it behaves quite similarly in different pictures in the feature space. On the contrary, when it moves violently, its performance may not be the same as the previous one. Therefore, if we use a time constraint to divide the samples (only then the adjacent amounts of time can be gathered together), then the data set can be identified when the target performs a slight performance change. We use human memory to model these data clusters and use reliable memory to represent large clusters that are perceived over time. In these texts, the early memories with more sample support are more reliable than the recent memories supported by few samples, especially when the picture change offset error accumulates. Therefore, the tracker can recover the offset error from the earlier memory by selecting the highly correlated sample.
Based on these studies, we propose a new tracking framework that can find autocorrelation representations in continuous pictures and then store reliable memories for long-term robust visual tracking. First, we designed a DFT-based visual tracker. It can accurately detect a large number of tracking samples and preserve good memory while ensuring real-time performance. Then we propose a new clustering method using time constraints. It can find clear and reliable memories from previous screens, which can help our tracker to reduce offset errors. The inherent correlation of the data stream obtained in this way ensures that the integral image is carefully designed to converge at a faster rate. As far as we know, the time-limited clustering method proposed by us is quite novel in visual flow data analysis. Its convergence speed and good performance reflect its great potential in online video problems. In particular, it can find data clusters (ie, reliable memory) in previously tracked samples, and it also allows our tracker to reduce offset errors. The implementation results show that our tracker is quite good at handling offset errors and achieves the best performance currently available on the current benchmark data set. What's more, it can perform robust tracking in videos with more than 4000 frames, and other methods cannot be accurately tracked in early pictures.
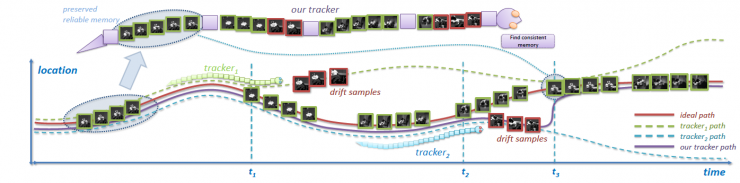
Figure 1 briefly introduces the logic of our method
2. Visual tracking based on cyclic architecture
Some recent studies have used Discrete Fourier Transform (DFT) and use a cyclic architecture for the target area, achieving the highest accuracy of the minimum computational cost at the current state of the art. In this section, we will briefly introduce these methods that are highly relevant to our work.
Assuming that Xâ‹´RL is a vector of image blocks of size MXN, centered on the target center area (L=MXN), our goal is to find the RLS function that can minimize the cost:
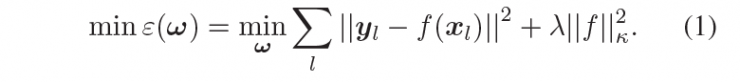
Formula One
Formula one can also be expressed like this

Formula two
The function in formula (2) is convex and differentiable, it has a closed (analytic) form of solution

It can also be expressed like this

Separation of Equation 3 is performed in the Fourier domain, so it is performed on an elemental basis. In practice, α does not need to be calculated from A, so fast detection can be performed on a given image block z:
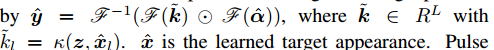
The pulse peak in Y shows the target conversion of the input image z. A detailed derivation process is described in [Gray, 2005; Rifkin et al., 2003; Henriques et al., 2012].
Although the recent methods MOSSE and ACT have different core function configuration features (for example, the MOSSE caused by the core k generated by the point, and the later two caused by the RBF core), they all use simple linearity in the current frame p. The combined learning target appearance model {xp, Ap} passes
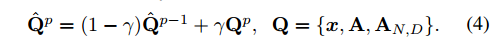
The CSK directly updates its ranking coefficient Ap by Equation 4, and for stability goals, MOSSE and ACT update the denominator ApD of the molecule Apn and the coefficient Ap, respectively. The learning rate γ is a trade-off parameter for long-term memory and model adaptation. After expanding equation 4, we get:

All three methods have a memory index reduction mode: the learning rate γ is usually very small, for example γ = 0.1, and the effect of the sample {xj, Aj} on determining the frame j after 100 frames is negligible. In other words, the tracer-based learning rate cannot accurately trace the traces of the sample before it helps suppress the cumulative drift error.
3. The proposed method
In addition to the above-mentioned convolution-based visual tracker, many other trackers use similar structures such as Q ˆ p = (1-γ) Q ˆ p-1 + γQp (learning rate parameter γ (0, 1 ] And there is a drift problem) updating their model Q.
We have found that smooth movements usually provide consistent appearance cues that can be modeled as reliable memories and recover paths from drift problems (due to fierce appearance changes). In this section, we first introduced our novel framework, which can ensure rapid detection while processing a large number of samples. Later, we elaborated on the details of intelligently sorting past samples into different and reliable clusters (allowing our tracker to resist drift errors).
3.1 Large sample loop tracker
Given a positive sample xp at frame p, we want to create an adaptation model {xp,Ap} to quickly detect the next sample of p+1 frames with image z:
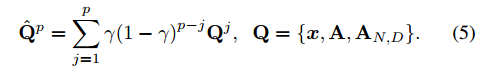

As shown, the adaptive learning appearance xp is a combination of the xp attention in the previous sample p and the fixed ratio γ. The coefficient {βj}p-1j=1 represents the correlation between the current evaluated appearance xp and the previous appearance {xj}p-1j=1. Selecting {βj}p-1j=1 should make the model satisfy: 1) adapt to new appearance changes, 2) consist of past appearance to avoid drifting. In this paper, we discuss the use of biased previously reliable memory settings {βj}p-1j=1, which can provide our tracker with very high robustness to avoid drift errors. We discussed how to find these reliable memories in Section 3.2 and introduced the correlation of {βj}p-1j=1 in Section 3.3.
Now, we focus on finding a set of classification coefficients α that are suitable for learning the consistency of the appearance Xp and the adaptability of the current appearance xp. Based on Equation 1 and Equation 2, we derive the following cost function to minimize:

We find that the adaptive learning appearance x^p should approximate the current xp because it is close to the combination of the past {xj}p-1j=1 appearance and the current appearance xp, as shown in Equation 7. Note the two kernel matrices Kp and K^p
(And their linear combination λI) is semi-positive definite. By connecting equation 8 and

As long as a suitable coefficient {βj}p-1j=1 is found, we can establish the detection model {x^p, A^p} by Equation 7 and Equation 9. In the next frame p+1, rapid detection can be performed by Equation 6 with this model.
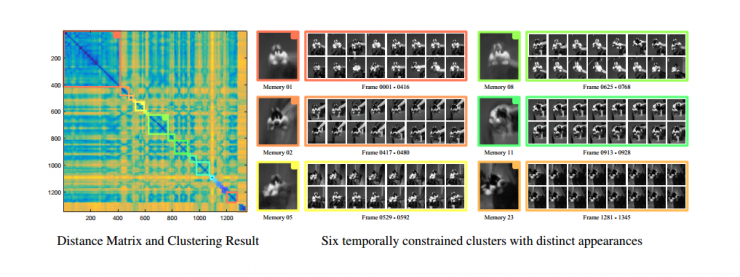
Fig. 2: Left: distance matrix D as described in Algorithm 1, right: For intuitive understanding, six representative groups with corresponding color border boxes are shown. The image blocks in the large bounding box are the average appearance of the current population (memory), while the small image blocks are the samples uniformly selected in the time domain from each cluster.

Algorithm 1
3.2 Time Constrained Clustering
In this section, we introduce time-constrained clustering—learning differences and reliable memory from input samples (in a very fast manner). In conjunction with ordered memory (section 3.3), our tracker is robust to inaccurate tracking results and can recover from drift errors.
Assume that a set of positive samples is given in frame P:
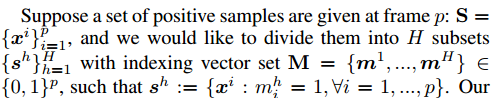
Our goals are as follows: 1) The samples in each subset sh have high correlation; 2) The samples from different subsets have relatively large appearance differences, so their linear combinations are vague, even ambiguous description tracking Targets (for example, samples of different opinions from different targets). So it can be modeled as a general clustering problem:

This is a discrete optimization problem called NP-hard. By adjusting the number of subsets M to a fixed constant K, the k-means clustering can converge to a local optimum.
However, in the process of visual tracking, we do not know the sufficient number of clusters. At the same time, too many clusters can lead to overfitting problems, while too few clusters can cause ambiguity. More crucially, once we allow random combinations of samples during clustering, any cluster has the risk of introducing a drift error into the sample, even if it is the same as the wrongly labeled sample, which in turn will reduce the build-up on them. The performance of the model.
One of the important findings is that in the time domain, the mutual closure of target appearances may form a distinctive and consistent pattern, such as reliable memory. If, over a period of time, a perfectly tracked target moves in such a way that there are no large rotations and no large angle changes, its vector characteristics will have a higher similarity when compared with features of different angles. In order to find these memories, we add a time constraint to Equation 10:
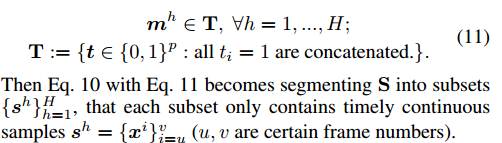
However, the constraints of this new problem are separated from each other, and it is very difficult to achieve global optimization. Therefore, we have designed a very ambitious algorithm, such as Algorithm 1, which starts from the tiny state of the p subset. This algorithm attempts to reduce the regularization r(|M|) of the original function in formula 10 by combining the adjacent subsets sh and sh+1, but it increases the distance of the average sample.
Through the ingenious use of Integral Image, the evaluation operation of each joint step in algorithm 1 only needs to use O(1) runtime in integral image J, and each iteration only takes O(p) operation. The entire calculation takes place at the bottom of the double tree, even in the worst case O(p log p). There are more than 1000 examples on the desktop but the runtime is less than 30 ms. In the design of the experiment, we can see that the proposed algorithm is sufficient to discover the set of outstanding features (reliable memory) for our tracker.
3.3 Tracking Framework Workflow
In our framework, we have used two feature libraries, one of which is to collect positive examples across the framework and the other is (mentioned by U) to collect learning and memory. Each memory is u∈U and includes a certain number of instances
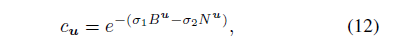
When Nu denotes the number of instances in memory u, then Bu is the number of frames that memory u just started. This memory confidence is consistent with our hypothesis; the more instances of memory in the initial period are more stable and less susceptible to incremental migration errors. For each framework, the translation that we started with for the evaluation goal will use Equation 6 to detect the target, and then we will use the new instance and Equation 7 and Equation 9 to update our appearance model {ˆxp, ˆAp}.
The correlation coefficient can be calculated by the following formula:

To update the memory, we use Algorithm 1 to collect positive instances in the first feature library and integrate them into “memoryâ€; all instances except the last one are added to U. When |U| reaches its critical value, the memory's memory confidence will be minimized and will immediately be abandoned.
4. Experiment
Our framework is implemented in Matlab, which runs at speeds of 12fps to 20fps, an Intel Xeon(R) 3.5GHz CPU on the desktop, a Tesla K40c video memory card, and 32GB of RAM. The adaptability ratio γ was empirically set at 0.15 in all tests. The recovery rate is 1.2 times the average covariance of the first 40 frames of each video. The maximum value of memory |U | is set to 10 and the maximum value of (Nu) is 100.
4.1 Time Constrained Clustering Evaluation
To confirm our hypothesis: Time-constrained clustering evaluation is to track instances in time series and form a trustworthy and identifiable pattern. Based on the tracking results, we calculate the off-line positive instances according to algorithm 1. Because the previous collected instances will affect later collections, our algorithm will give accurate and identical results in offline or online mode. Due to space limitations, we explain the results in the Sylvester sequence in Figure 2. As shown in the figure, the target experienced a change in light, after 1345 frames were rotated in or out of plane. The left part shows the matrix D distance, which can be calculated by Algorithm 1. The pixel Dij is dark blue (light yellow) suggesting that the distance in the set of instances of instance Xi and instance Xj is near (distant). Different frame colors represent different time-constrained clusters. The right part shows six different clusters that correspond to the different frame colors in the matrix. Memory 1 and Memory 8 are the two largest clusters containing a large number of similarly shaped instances (blue). Memory 11 represents only 16 instances of the cluster. Due to its late appearance and limited number of instances, the memory confidence cu is so low that it is unlikely to replace the existing reliable memory.
4.2 Acceleration through deep CNN
The inherent requirement of our tracker for searching for similar patterns (memory) is that the frame global and target detection tasks overlap. Recently, the convolutional neural network (CNN) has rapidly developed. Faster-RCNN detects the common convolutional layer by using the target proposed target and its detection speed reaches ≥5 fps. To ensure the reliability of the memory, we put a comprehensive perspective on the tracker and improved the FC layer of the Faster-RCNN explorer, because we found that learning enough video memory can help the tracker to solve the problem. The problem caused. Through the existing rough exploration, our tracker can explore from the nearest range to the target, thus further ensuring that the tracking results are accurate and feasible, but there is a danger of error. Note that we only adjusted CNN once, and it took 3000 iterations on the Tesla K40c to run for 150 seconds. When the tracking task takes too long, for example, over 3,000 frames, the average fps will exceed 15, but it is worth improving the roughness. In the next article, we will show that CNN detection is performed every 5 frames, each time it takes less than 0.1 seconds.
4.3 Quantitative analysis
First we will evaluate our method in 50 challenging sequences. Starting from OTB-2013, we will compare them with 12 advanced methods: ACT, AST, ASLA, CXT, DSST, KCF, LOT, MEEM , SCM, Struct, TGPR TLD, VTD.

Figure 3: Comparison of 50 sequence trace results for the OTB-2013 dataset. Our tracker is referred to by RMT and performs best. The performance of MEEM, TGPR, and KCF is closer to our performance. Only the first 10 of the 12 trackers are visible. Its success rate is visible after each mode name.

Table 1: The average pixel-by-pixel error based on the center position (smaller is better), the tracking results are compared and compared to 4 longer videos, over 13,000 frames. The average performance is judged by the accuracy of the frame.
We use code published by public resources (for example, OTB-2013) or versions published by the author. All the parameters of each tracker in the test are fixed. Figure 3 shows only one successful graph that passed the evaluation (OPE) standard across the entire data set. Our tracker is RMT (Credit Memory Tracker) which has the best performance, but MEEM, TGPR, KCF and DSST are not bad. It is worth noting that TGRP's idea of ​​building trackers based on additional examples and MEEM's use of tracker captures can all be understood as making full use of early-memory patterns, which is also closely related to our approach. Our tracker has performed in a challenging scenario as shown in Figure 3: blockage, plane rotation, disappearance, and rapid movement. The main reason for this is that our tracker has a large amount of credible memory and a full range of perspectives, so even if there are significant changes in the external features, it can again focus on the target.
To explore the robustness of the tracker we use and the resistance to migration errors in long-term tasks, the tracker was used in four long sequences of over 13,000 frames. The convolution filter layer has previously been evaluated based on the methods we use: MOSSE, ACT, DSST, KCF, and MEEM, and detector-based TLD methods. To demonstrate the effectiveness of "trusted memory" in blocking non-used CNN examples, we also show the comparison of CNN-boosted DEET and KCF. MOSSE often loses the target in early frames, but KCF, ACT, and DSST can accurately track the target in hundreds of frames, but they also lose the target after 600 frames. MEEM showed better strength in video Motocross over 1700 frames, but it can't adapt to large-scale changes, and the results will often go wrong. Improvements from CNN to KCF and DSST are limited because CNN is trained with contaminated examples, which can lead to inaccuracies (even false alarms) unless these trackers can remove themselves from the CNN training process. , just like the method we used, otherwise the results will not improve. The trackers and TLDs we use perform better in all videos than other trackers because of the use of a full-field tracker for target locking. However, if it is based on an off-line tree mode, the positive examples of TLD misunderstandings will slow down, leading to detection errors or inaccurate tracking results. Conversely, training by CNN detectors and our trusted memory, our tracker will only be affected by a small number of false detections. It can accurately locate the target in all frames and give accurate position and target size before the last frame of the four videos.
5 Conclusion
In this paper we propose a novel frame tracking method that can explore similarly shaped aggregates chronologically across all traced instances and then store reliable memories for visual tracking. This novel clustering method and time limit are all well-designed to help trace the useful memory from a large number of instances and use for precise detection, but at the same time guarantee its real-time performance. Experiments have shown that our method has outstanding ability to recover from long-term tracking task migration errors, and it also surpasses other advanced methods.
Follow this example video
Via IJCAI2016
Reviews
Visual tracking is a fundamental and challenging issue for computer vision and artificial intelligence. This paper proposes a new visual tracking method for this problem. This method can intelligently detect reliable patterns from a large number of videos to reduce long-term tracking tasks. Offset error in. At present, research in this direction has made great progress. However, there are still many problems to be solved in the light intensity and angle change, disorderly background, etc., and combined with the recent online learning tracking-detection method has achieved very good results. However, there are still some problems such as large amount of calculation. However, the method of recording the change of target appearance by using the learning rate has the problem of the attenuation of the previous sample memory index, which can not eliminate the accumulated drift error of the tracking process. For this reason, the paper designs a circulant tracker based on Discrete Fourier Transform (DFT) using reliable memory information by exploring available target appearance clusters to protect reliable memory information in video. The tracker not only has a high tracking success rate, but also has a certain real-time nature.
PS : This article was compiled by Lei Feng Network (search “Lei Feng Network†public number) and it was compiled without permission.
Ip20 Ultra Thin Hce Power,Led Strip With Driver,Indoor Light Driver,Strip Led Power
Jiangmen Hua Chuang Electronic Co.,Ltd , https://www.jmhcpower.com