
Lei Feng Network (search "Lei Feng Net" public concern) : This article is transferred from the capital of statistics. The original text was compiled from Zhang Zhihua's two lectures at the 9th China R Language Conference and Shanghai Jiaotong University. Zhang Zhihua is a professor at the Department of Computer Science and Engineering of Shanghai Jiaotong University, an adjunct professor at the Data Research Center of Shanghai Jiaotong University, and a doctoral tutor of dual disciplines in computer science and technology and statistics. Prior to joining Shanghai Jiaotong University, he was a professor at the School of Computer Science, Zhejiang University and an Adjunct Professor at the Statistical Science Center of Zhejiang University. Ms. Zhang is mainly engaged in teaching and research in artificial intelligence, machine learning, and applied statistics. He has published more than 70 papers in international academic journals and important computer science conferences. He is a guest commentator for the “Mathematical Review†of the United States. The Executive Editor of Journal of Machine Learning Research, an international machine learning flagship publication. His open classes "Introduction to Machine Learning" and "Statistical Machine Learning" received extensive attention.
The recent strong rise of artificial intelligence or machine learning, especially the past man-machine battle between AlphaGo and Korean player Li Shishi, has once again given us a glimpse of the great potential of artificial intelligence or machine learning technology, and it has also deeply touched me. . In the face of this unprecedented technological change, as a scholar who has been engaged in teaching and research in the field of statistical machine learning for more than 10 years, I hope to take this opportunity to share with you some of my personal reflections and reflections.

My speech mainly consists of two parts. In the first part, I first discuss the inherent nature of machine learning, especially its connection with statistics, computer science, and operational optimization, as well as its relationship with industry and entrepreneurship. . In the second part, we try to use concepts such as “multilevelâ€, “adaptiveâ€, and “average†to concise some of the research ideas or ideas behind the multitude of machine learning models and calculation methods.
Part I: Review and Reflection
1, what is the machine learning
Undoubtedly, big data and artificial intelligence are the most fashionable terms today. They will bring profound changes to our future lives. Data is fuel, intelligence is the goal, and machine learning is the rocket, the technological path to intelligence. Machine learning masters Mike Jordan and Tom Mitchell believe that machine learning is the intersection of computer science and statistics, and at the same time it is the core of artificial intelligence and data science.
"It is one of today's rapidly growing technical fields, lying at the intersection of computer science and statistics, and at the core of artificial intelligence and data science" ---MI Jordan
In layman's terms, machine learning is the mining of useful values ​​from data. The data itself is dead and it does not automatically present useful information. How can we find valuable things? The first step is to give an abstract representation of the data, and then model it based on the representation, and then estimate the parameters of the model, that is, the calculation. In order to deal with the problems brought about by large-scale data, we also need to design some efficient means of implementation.
I interpret this process as machine learning equal to matrix + statistics + optimization + algorithm. First, when the data is defined as an abstract representation, a matrix or a graph is often formed, and the graph can actually be understood as a matrix. Statistics is the main tool and approach for modeling, and model solving is mostly defined as an optimization problem. In particular, the frequency statistics method is actually an optimization problem. Of course, the calculation of the Bayesian model involves a random sampling method. When we talked about the concrete realization of the big data problem, we need some efficient methods. There are many good techniques in computer science algorithms and data structures that can help us solve this problem.
Drawing on Marr's definition of three-level theory of computer vision, I divided machine learning into three levels: elementary, intermediate, and advanced. The primary stage is data acquisition and feature extraction. The intermediate stage is data processing and analysis. It also contains three aspects. The first is the application problem orientation. In short, it mainly applies existing models and methods to solve some practical problems. We can understand it as data mining. Second, based on The need to apply problems, to propose and develop models, methods and algorithms, and to study the mathematical principles or theoretical foundations that underpin them, I understand that this is the core content of machine learning disciplines. Third, achieve some intelligence through reasoning. Finally, the advanced stage is intelligence and cognition, that is, the goal of achieving intelligence. From here, we see that data mining and machine learning are essentially the same. The difference is that data mining is more grounded on the database side, and machine learning is closer to the smart side.
2, statistics and calculations
Machine scientists usually have strong computing power and intuition to solve problems, while statistical parents have strong modeling ability in theoretical analysis. Therefore, the two have very good complementarities.
Boosting, SVM, and sparse learning are machine learning circles and statistics circles. In the past ten years or nearly twenty years, they have been the most active direction. Now it is hard to say who has contributed more than anyone else. For example, the theory of SVM was proposed by Vapnik et al. very early, but the computer industry invented an effective solution algorithm, and later there is a very good realization of the code is being open source for everyone to use, so the SVM becomes a classification algorithm A benchmark model. For another example, KPCA is a non-linear dimensionality reduction method proposed by computer scientists. In fact, it is equivalent to classical MDS. The latter is very early in the statistics community, but if there is no new discovery in the computer industry, some good things may be buried.
Machine learning has now become a mainstream of statistics, and many well-known statistics departments have recruited Ph.D. in machine learning as instructors. Computing has become more and more important in statistics. Traditional multivariate statistical analysis uses matrix as the calculation tool, and modern high-dimensional statistics use optimization as the calculation tool. On the other hand, the computer science discipline offers advanced statistics courses, such as the core course "statistical process" in statistics.
Let's look at what kind of machine learning is in computer science. John Hopcroft, the author of a recently published book "Foundation of Data Science, by Avrim Blum, John Hopcroft, and Ravindran Kannan," was the Turing Award Winner. In the forefront of this book, it is mentioned that the development of computer science can be divided into three stages: early, middle, and present. The early days allowed the computer to run. Its focus was on developing programming languages, compiling principles, operating systems, and studying the mathematical theory that underpinned them. The mid-term is to make computers useful and efficient. The focus is on the study of algorithms and data structures. The third stage is to make computers more widely available. The development focus has shifted from discrete mathematics to probability and statistics. Then we see that the third stage is actually what machine learning is concerned about.
Nowadays, the computer industry nicknamed machine learning "the all-round discipline" and it is ubiquitous. On the one hand, machine learning has its own system of disciplines; on the other hand, it has two important radiation functions. The first is to provide solutions to problems and methods for applied disciplines. To put it plainly, for an applied discipline, the purpose of machine learning is to translate difficult mathematics into pseudocode that allows engineers to write programs. The second is to find new research questions for some traditional disciplines, such as statistics, theoretical computer science, and operational optimization.
3, Enlightenment of Machine Learning Development
The development of machine learning tells us that developing a discipline requires a pragmatic attitude. The concept and name of fashion will undoubtedly have a certain role in promoting the popularization of disciplines. However, the fundamentals of the discipline are the problems, methods, techniques, and foundations of the research, as well as the values ​​that are generated for the society.
Machine learning is a cool name. It is simply understood literally. Its purpose is to make machines as capable as humans. However, as we have seen above, during its 10-year golden period of development, the machine learning community did not excessively speculate on “intelligence,†but focused more on the theoretical basis for introducing statistics to establish disciplines. Data analysis and processing, with unsupervised learning and supervised learning as two major research issues, proposes and develops a series of models, methods, and computational algorithms to solve practical problems facing the industry. In recent years, in response to the tremendous increase in driving and computing power of big data, a number of low-level architectures for machine learning have been developed, and the strong rise of deep neural networks has brought profound changes and opportunities to the industry.
The development of machine learning also interprets the importance and necessity of interdisciplinarity. However, this kind of crossover is not simply a matter of knowing a few terms or concepts from each other, but it requires real fusion. Professor Mike Jordan is both a first-class computer scientist and a first-rate statistician, so he can shoulder the burden of establishing statistical machine learning. And he is very pragmatic and never mentions the empty concepts and frameworks. He followed a bottom-up approach, starting with specific issues, models, methods, algorithms, etc., and then systematically step by step. Prof. Geoffrey Hinton is the world’s most famous cognitive psychologist and computer science scientist. Although he had achieved great success early on and had a great reputation in the academic world, he has been active in the field and writing code himself. Many of the ideas he proposed are simple, feasible and very effective, and are therefore called great thinkers. It is because of his wisdom and strength that deep learning technology ushered in a revolutionary breakthrough.
The discipline of machine learning is also compatible and accepted. We can say that machine learning is made up of academia, industry, entrepreneurship (or competition), and so on. The academic world is the engine, the industry is the driving force, and the entrepreneurial world is the vitality and future. Academics and industry should have their own responsibilities and division of labor. The responsibility of the academic community lies in the establishment and development of the discipline of machine learning and the training of specialized personnel in the field of machine learning. Large projects and large projects should be driven by the market and implemented and completed by the industry.
Part II: Several Simple Research Ideas
In this part, my concern is back to the study of machine learning itself. The machine learning content is extensive and profound, and new methods and new technologies are constantly being proposed and discovered. Here, I try to use concepts such as "multi-level", "adaptive", and "average" to simplify the research ideas and ideas behind numerous and varied machine learning models and calculation methods. It is hoped that these will be inspiring for everyone to understand some of the existing models, methods and future research of machine learning.
1. Hierarchical
First of all, let's pay attention to the "multilevel" technical idea. We look specifically at three examples.
The first example is the implicit data model, which is a multi-level model. As an extension of the probability map model, the implicit data model is an important multivariate data analysis method. Implicit variables have three important properties. First, stronger independent boundary correlations can be replaced by weaker conditional independent correlations. The famous de Finetti said the theorem supports this. The theorem states that a set of random variables that can be exchanged can be represented as a mixture of conditional random variables if and only if the parameters are given. This gives a multilevel representation of a set of random variables that can be exchanged. That is, one parameter is first extracted from a distribution, and then based on this parameter, the random variable is extracted from a certain distribution independently. Second, it is possible to facilitate calculations by introducing techniques for implicit variables, such as the expectation of maximum algorithms and more generalized data expansion techniques. Specifically, some complex distributions such as t-distribution and Laplace distribution can be simplified by expressing them as Gaussian-scale mixtures. Third, the hidden variable itself may have some interpretable physical meaning, which is exactly in line with the application scenario. For example, in the implicit Dirichlet distribution (LDA) model, implicit variables have the meaning of a certain topic.
The first example is the implicit data model, which is a multi-level model. As an extension of the probability map model, the implicit data model is an important multivariate data analysis method. Implicit variables have three important properties. First, stronger independent boundary correlations can be replaced by weaker conditional independent correlations. The famous de Finetti said the theorem supports this. The theorem states that a set of random variables that can be exchanged can be represented as a mixture of conditional random variables if and only if the parameters are given. This gives a multilevel representation of a set of random variables that can be exchanged. That is, one parameter is first extracted from a distribution, and then based on this parameter, the random variable is extracted from a certain distribution independently. Second, it is possible to facilitate calculations by introducing techniques for implicit variables, such as the expectation of maximum algorithms and more generalized data expansion techniques. Specifically, some complex distributions such as t-distribution and Laplace distribution can be simplified by expressing them as Gaussian-scale mixtures. Third, the hidden variable itself may have some interpretable physical meaning, which is exactly in line with the application scenario. For example, in the implicit Dirichlet distribution (LDA) model, implicit variables have the meaning of a certain topic.
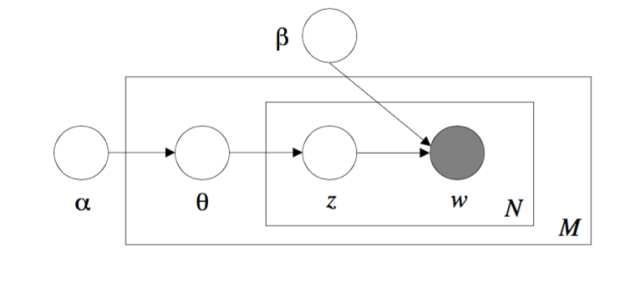
Laten Dirichlet Allocation
For the second example, let's look at the multi-level Bayesian model. In the MCMC sampling posterior estimation, the uppermost hyperparameter always needs to be given first. Naturally, the convergence performance of the MCMC algorithm is dependent on these given hyperparameters. If we choose these parameters, it is not good. The experience, then one possible approach we add a layer, the more the number of layers, the dependence on the selection of hyperparameters will weaken.
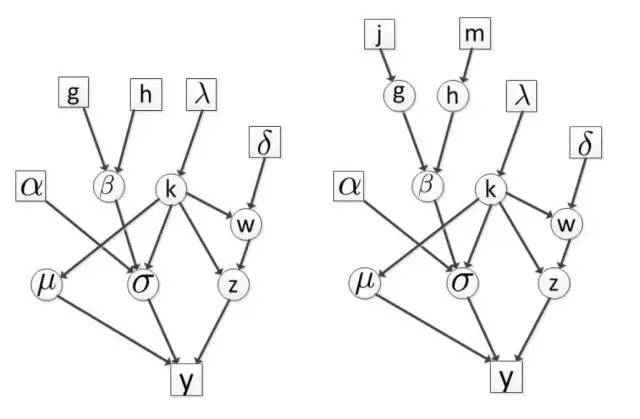
Hierarchical Bayesian Model
In the third example, deep learning implies multiple levels of thinking. If all the nodes are laid flat and then fully connected, it is a fully connected graph. The CNN depth network can be seen as a regularization of a structure of a fully connected graph. Regularization theory is a very central idea of ​​statistical learning. CNN and RNN are two deep neural network models, which are mainly used in image processing and natural language processing. Research shows that multi-level structures have stronger learning capabilities.
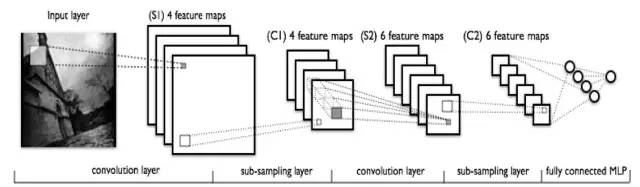
Deep Learning
2. Adaptive
Let's look at the adaptive technology idea. We use a few examples to see the effect of this idea.
The first example is the adaptive importance sampling technique. Important sampling methods can generally improve the performance of uniform sampling, while adaptation further improves the performance of important samples.
The second example is the adaptive column selection problem. Given a matrix A, we hope to select some columns from it to form a matrix C, then use CC^+A to approximate the original matrix A, and hope that the approximation error is as small as possible. This is a NP hard problem. In practice, an adaptive method can be used to produce a very small portion of C_1, thereby constructing a residual, by which a probability is defined, and then a fraction of C_2 is taken with probability, and C_1 and C_2 are combined to form a residual. C.
The third example is an adaptive randomized iterative algorithm. Consider an empirical risk minimization problem with regularization. When training data is very large, the batch calculation method is very time consuming, so a random approach is usually used. The presence of a stochastic gradient or random dual gradient algorithm can give an unbiased estimate of the parameter. By introducing adaptive techniques, the estimated variance can be reduced.
The fourth example is the Boosting classification method. It adaptively adjusts the weight of each sample, specifically, increases the weight of the error sample, and reduces the weight of the sample pair.
3. Averaging
In fact, boosting contains the average idea, that is, the technical thought that I want to talk about last. Simply put, boosting integrates a group of weak classifiers to form a strong classifier. The first benefit is that you can reduce the risk of fitting. Second, you can reduce the risk of falling into a local situation. Third, you can expand the hypothesis space. Bagging is also a classic ensemble learning algorithm. It divides the training data into several groups and then trains the models on small data sets respectively. Through these models, the strong classifiers are combined. In addition, this is a two-tier integrated learning approach.

The classical Anderson acceleration technique is to accelerate the convergence process with the average idea. Specifically, it is a superposition process that obtains a weighted combination by solving a residual minimum. The benefit of this technique is that it does not add too much computation, and it can often make numerical iterations more stable.
Another example of using averages is in distributed computing. In many cases, distributed computing is not synchronous and asynchronous. What if it is asynchronous? The simplest is to do each independently, to average all the results at some point, distribute it to each worker, and then run each independently. It's like a hot start process.
As we have seen, these ideas are usually used in combination, such as boosting models. Our multi-level, adaptive, and average thinking is straightforward, but it is also very useful.
304 stainless steel heating element
Removable frying pot&basket with non-stick coating
Removable and heat insulation handle for frying basket
Automatic shut-off with ready alert
Prevent slip feet
Heat resistant material inside enclosure
With fan guard,more safety
Certificates: GS CE CB SAA RoHS LFGB
Colour: customized
English manual&cookbook
Air Cooker Fryer,Air Fryer Oil Free,Oil Free Air Fryer,Electric Oil Free Air Fryer
Ningbo Huayou Intelligent Technology Co. LTD , https://www.homeapplianceshuayou.com